层标准化详解(Layer Normalization) |
您所在的位置:网站首页 › keras 归一化 › 层标准化详解(Layer Normalization) |
层标准化详解(Layer Normalization)
|
为什么Batch Normaization难以应用于RNNs?
Batch Normalization使用mini-batch的均值和标准差对深度神经网络的隐藏层输入进行标准化,可有效地提升训练速度。对于前向神经网络应用Batch Norm,使用简单SGD优化器,训练速度也能有较大提升。 BN的效果受制于batch的大小,小batch未必能取得预期效果; 对于前向神经网络可以很直接地应用BN,因为其每一层具有固定的神经元数量,可直接地存储每层网络各神经元的均值、方差统计信息以应用于模型预测,但在RNNs网络中,不同的mini-batch可能具有不同的输入序列长度(深度),计算统计信息比较困难,而且测试序列长度不能大于最大训练序列长度; Barch Normalization也很难应用于在线学习模型,以及小mini-batch的分布式模型; torch内部有两种BatchNorm,分别是BatchNorm1D和BatchNorm2D,BatchNorm1D作用于2维张量(B*D,存储D个统计量),BatchNorm2D作用于4维张量(B*C*W*H,存储C个统计量) NLP任务中的张量多为3维,B*N*D,需存储序列长度上的统计量,而不同batch的序列长度不一致,不好统计,而且推理阶段的序列长度不能大于训练时所用的最大长度。 如何对RNNs网络进行标准化?网络层的输出经过线性变换作为下层网络的输入,网络输出直接影响下层网络输入分布,这是一种协变量转移的现象。我们可以通过 固定网络层的输入分布(固定输入的均值和方差) 来降低协变量转移的影响。 BN对同一mini-batch中对不同特征进行标准化(纵向规范化:每一个特征都有自己的分布),受限于batch size,难以处理动态神经网络中的变长序列的mini-bach。 RNNs不同时间步共享权重参数,使得RNNs可以处理不同长度的序列,RNNs使用 Layer Normalization 对不同时间步进行标准化(横向标准化:每一个时间步都有自己的分布),从而可以处理单一样本、变长序列,而且 训练和测试处理方式一致。 Batch Normalization和Layer Normalization的应用 对于CNNs图像x=shape(batch_size, channels, height, weight),则 bn_mean=np.mean(x, axis=(0, 2, 3)), shape=(1, channels, 1, 1) 对于RNNs序列x=shape(batch_size, seq_len, hidden_size), 则 ln_mean=np.mean(x, axis=2), shape=(batch_size, seq_len, 1)对于前向神经网络的第 l l l隐藏层(等价于RNNs时刻 l l l对应的隐藏层),令 a l \boldsymbol a^l al表示输入向量(前层网络输出加权后的向量), H H H表示隐藏单元数量,则 Layer Normalization 的均值和方差统计量为 μ l = 1 H ∑ i = 1 H a i l , σ l = 1 H ∑ i = 1 H ( a i l − μ l ) 2 \mu^l = \frac{1}{H}\sum_{i=1}^Ha^l_i,\quad \sigma^l=\sqrt{\frac{1}{H}\sum_{i=1}^H(a^l_i-\mu^l)^2} μl=H1i=1∑Hail,σl=H1i=1∑H(ail−μl)2 同层网络的所有隐藏单元共享均值和方差。 对于标准RNN,若当前输入为 x t \boldsymbol x^t xt,上一隐藏状态为 h t − 1 \boldsymbol h^{t-1} ht−1,则加权输入向量(非线性单元的输入)为 a t = W h h h t − 1 + W x h x t \boldsymbol a^t=W_{hh}\boldsymbol h^{t-1}+W_{xh}\boldsymbol x^t at=Whhht−1+Wxhxt 则对输入向量进行层标准化,再进行 缩放和平移(用于恢复非线性)得标准化后输入 y \boldsymbol y y: y = g ⊙ a ^ t + b , a ^ t = a t − u t σ t \boldsymbol y= \boldsymbol g\odot\hat \boldsymbol a^t+\boldsymbol b,\quad \hat \boldsymbol a^t=\frac{\boldsymbol a^t-u^t}{\sigma^t} y=g⊙a^t+b,a^t=σtat−ut 对于使用LN的RNNs,每个时刻加权后的输入通过标准化被重新调整在合适的范围,很大程度避免了梯度消失、梯度爆炸问题,隐藏状态的传递更加稳定。 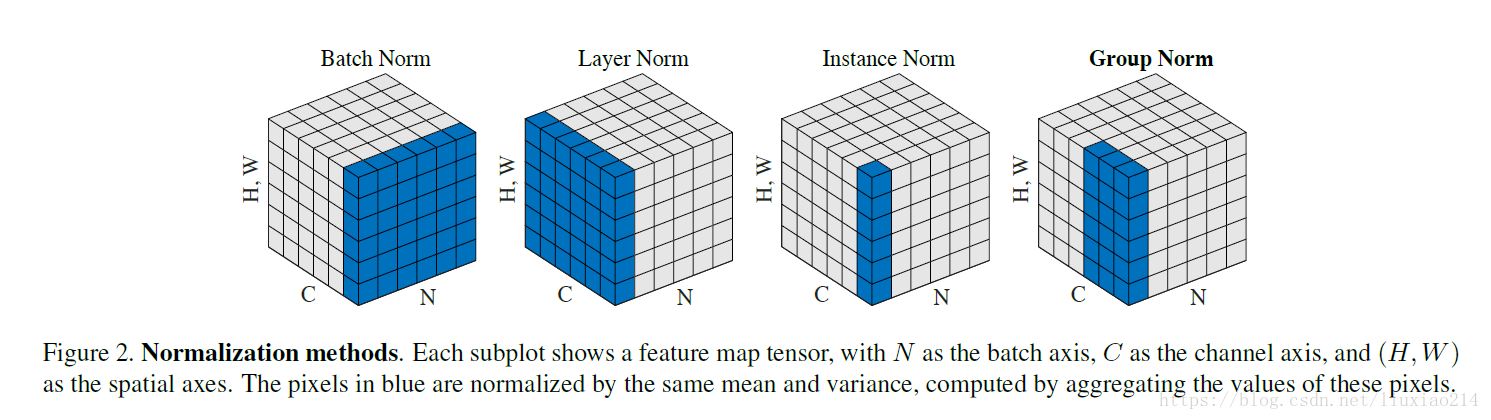 Torch中的LayerNorm、BatchNorm1D和BatchNorm2D对比
import torch
import numpy as np
with torch.no_grad():
# LayerNorm基于最后一维统计量执行标准化,即最后一维向量内部执行标准化
print("\n------ TEST LAYER NORM ------")
x = torch.normal(1., 2., (2, 4, 6))
layernorm = torch.nn.LayerNorm(x.size(-1), eps=0, elementwise_affine=True)
layernorm.training = False
std, mean = torch.std_mean(x, -1, unbiased=False)
x1 = (x - mean[:, :, None]) / std[:, :, None]
x2 = layernorm(x)
print(np.round(x1.numpy(), 4) == np.round(x2.numpy(), 4))
# BatchNorm1D基于最后一维统计量执行标准化
print("\n------ TEST BATCH NORM 1D ------")
x = torch.normal(1., 2., (4, 6))
# y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
batchnorm = torch.nn.BatchNorm1d(x.size(-1), eps=0., track_running_stats=False)
batchnorm.training = False
std, mean = torch.std_mean(x, 0, unbiased=False)
x1 = (x - mean[None, :]) / std[None, :]
x2 = batchnorm(x)
print(np.round(x1.numpy(), 4) == np.round(x2.numpy(), 4))
# BatchNorm2D基于第2维(Channel维度)统计量执行标准化
print("\n------ TEST BATCH NORM 2D ------")
# shape=(B, C, H, W)
x = torch.normal(1., 2., (2, 3, 4, 4))
b, c, h, w = x.size()
# y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
batchnorm = torch.nn.BatchNorm2d(c, eps=0., track_running_stats=False)
batchnorm.training = False
x1 = x.permute(0, 2, 3, 1).reshape(-1, c)
std, mean = torch.std_mean(x1, 0, unbiased=False)
x1 = (x1 - mean[None, :]) / std[None, :]
x1 = x1.view(b, h, w, c).permute(0, 3, 1, 2)
x2 = batchnorm(x)
print(np.round(x1.numpy(), 4) == np.round(x2.numpy(), 4))
Torch中的LayerNorm、BatchNorm1D和BatchNorm2D对比
import torch
import numpy as np
with torch.no_grad():
# LayerNorm基于最后一维统计量执行标准化,即最后一维向量内部执行标准化
print("\n------ TEST LAYER NORM ------")
x = torch.normal(1., 2., (2, 4, 6))
layernorm = torch.nn.LayerNorm(x.size(-1), eps=0, elementwise_affine=True)
layernorm.training = False
std, mean = torch.std_mean(x, -1, unbiased=False)
x1 = (x - mean[:, :, None]) / std[:, :, None]
x2 = layernorm(x)
print(np.round(x1.numpy(), 4) == np.round(x2.numpy(), 4))
# BatchNorm1D基于最后一维统计量执行标准化
print("\n------ TEST BATCH NORM 1D ------")
x = torch.normal(1., 2., (4, 6))
# y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
batchnorm = torch.nn.BatchNorm1d(x.size(-1), eps=0., track_running_stats=False)
batchnorm.training = False
std, mean = torch.std_mean(x, 0, unbiased=False)
x1 = (x - mean[None, :]) / std[None, :]
x2 = batchnorm(x)
print(np.round(x1.numpy(), 4) == np.round(x2.numpy(), 4))
# BatchNorm2D基于第2维(Channel维度)统计量执行标准化
print("\n------ TEST BATCH NORM 2D ------")
# shape=(B, C, H, W)
x = torch.normal(1., 2., (2, 3, 4, 4))
b, c, h, w = x.size()
# y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
batchnorm = torch.nn.BatchNorm2d(c, eps=0., track_running_stats=False)
batchnorm.training = False
x1 = x.permute(0, 2, 3, 1).reshape(-1, c)
std, mean = torch.std_mean(x1, 0, unbiased=False)
x1 = (x1 - mean[None, :]) / std[None, :]
x1 = x1.view(b, h, w, c).permute(0, 3, 1, 2)
x2 = batchnorm(x)
print(np.round(x1.numpy(), 4) == np.round(x2.numpy(), 4))
输出如下: ssh://[email protected]:22/home/merlin/anaconda3/envs/hermes/bin/python -u /data/ao/hermes/norm.py ------ TEST LAYER NORM ------ [[[ True True True True True True] [ True True True True True True] [ True True True True True True] [ True True True True True True]] [[ True True True True True True] [ True True True True True True] [ True True True True True True] [ True True True True True True]]] ------ TEST BATCH NORM 1D ------ [[ True True True True True True] [ True True True True True True] [ True True True True True True] [ True True True True True True]] ------ TEST BATCH NORM 2D ------ [[[[ True True True True] [ True True True True] [ True True True True] [ True True True True]] [[ True True True True] [ True True True True] [ True True True True] [ True True True True]] [[ True True True True] [ True True True True] [ True True True True] [ True True True True]]] [[[ True True True True] [ True True True True] [ True True True True] [ True True True True]] [[ True True True True] [ True True True True] [ True True True True] [ True True True True]] [[ True True True True] [ True True True True] [ True True True True] [ True True True True]]]] Process finished with exit code 0Reference 1.Ba, Jimmy et al. “Layer Normalization.” ArXiv abs/1607.06450 (2016): n. pag. 2.BatchNorm2d原理、作用及其pytorch中BatchNorm2d函数的参数讲解 |
【本文地址】
今日新闻 |
推荐新闻 |